Stock analysis is important, and there are a gazillion or so books, classes, seminars, workshops, etc. dedicated to helping you do it more effectively. The Chaikin Power Gauge model is one such approach and, I believe, the best one I’ve come across in a nearly 4-decade career during which I’ve pretty much seen it all. But no matter how much belief and commitment I or anyone else has toward an approach to analysis, we all need something else: Before we decide whether a stock is good, bad or in between, we need to decide which stocks to look at. This is a critical, and typically under-appreciated step. If you squander your time and resources looking at stocks that aren’t worthy of being considered, you’re setting yourself up for failure before you even start. On the other hand, if you can focus your efforts on a collection of stocks that has been sensibly pre-qualified much the way a successful sales person tries to pre-qualify leads rather than calling on every name that pops up at random, you’re much better positioned for success.

© Can Stock Photo / Medclips
Have you ever heard of Harry Markowitz, the Efficient Frontier or MPT (Modern Portfolio Theory)? If you have an MBA in Finance, you probably have (and may or may not remember it. These refer to a Nobel Prize-winning set of ideas that teach portfolio managers how to allocate holdings in such a way as to get the maximum possible return for whatever level of risk they choose, or exposure to the least amount of risk for whatever level of return they target. During the semester, we had to create and manage so-called “efficient” portfolios (paper portfolios of course; we were moneyless students). At the end of the term, not surprisingly, we all had show-and-tell to present our work.
Musing From The Back Benches of An MBA Portfolio Management Class
Sitting in my preferred location, the back row, and not having an internet-connected laptop with which to amuse myself (back in those pre-pc days, we had only two choices; pay attention or try to stay inconspicuous as we nodded off) I, paying attention that day, noticed an interesting trend developing as one classmate after another presented. The results achieved had nothing at all to do with how effectively anybody implemented the MPT. It was all about whether the collection of stocks it was being applied consisted of good or bad stocks.
Seriously! I understand that that may prompt a“Well . . . duh!” reaction. Stay with me.

© Can Stock Photo / makspongolii
In that low (by today’s standards) tech era, considering that we had to do a lot of work by hand with a small assist from the computer center (we made punch cards, brought them to the center, and came back a couple of days later to retrieve our mainframe printouts), we couldn’t just optimize full sets of S&P 500, or even Dow 30, constituents. We had to choose smaller subsets, and we were given the freedom to make our own individual choices. So there were, indeed, very stark differences in portfolio constituents we each used.
We never discussed these choices. We took them for granted and focused only on the cool stuff, the MPR. But during the show-and-tell, with the term and my grad-school time approaching its end, I gave myself license to start thinking less like a student and more like I thought I would when I got into the real world. And from that perspective, I found myself increasingly shocked that nobody, including the professor, seemed to be commenting on the choices of stocks whose weights would be optimized.
Although choices made to work with this group of stocks as opposed to that group flew completely under the radar, those unspoken choices based on who knows what, if any, criterion, accounted for about 100% of the relative degree success of each portfolio. (To be fair to Professor I-Forgot-His-Name, he measured success by one’s understanding of MPT. I, on the other hand, was thinking in terms of which classmates i thought might be good as real-world portfolio managers.)
The Real World View
Based on the opening he wrote for Chapter 9 of his classic One Up on Wall Street (Simon & Schuster, 2012 edition), legendary former Fidelity Magellan fund manger Peter Lynch also noticed the importance of the question of how one identifies stocks to be considered and expressed disdain for a then-commonplace practice:
If I could avoid a single stock, it would be the hottest stock in the hottest industry, the one that gets the most favorable publicity, the one that every investor hears about in the car pool or on the commuter train—and succumbing to the social pressure, often buys.
Yet investors still find stocks this way — often. This is functionally equivalent to getting ideas from CNBC, Fox Business or Bloomberg TV, where the flow of ideas depends on the combination of current events and which potential guests are available to show up to fill the time slots the producers need to fill. It’s functionally equivalent to contemporary web-site scrolls that present posts in something like chronological order with the most recent one on top.
How You Compile A List of Ideas Is A Difference Maker
The following is an extended quote from Chapter 4 of Screening the Market (Wiley, 2002) written by yours truly:
Suppose a magician came along and offered to help you invest in stocks. He refuses to do anything to improve your stock selection skills. So if you’re a good stock picker in the real world, you’ll stay good after he waves his magic wand. And if you’re a mediocre analyst, you’ll stay mediocre. But he does offer to let you choose whether the stock market goes up 20%, or down 5%. I’ll bet you’d accept the offer and choose a +20% market. You might still pick some duds. But wouldn’t you prefer to do your thing in a bull market that rises 20%?
Obviously, you can’t single-handedly influence the real world market. But you have considerable power to set the tone of your personal stock market, the tiny group from which you will make your choices. Let’s pretend the whole stock market consists of twenty companies. John Doe used a stock screen to create a list of ten potentially interesting growth opportunities. The ten stocks Bob Smith chooses to evaluate are the ones he heard about from his friends. Table 4.1 shows how the different “personal stock markets” impact each investor.
Table 4.1 Two User Designed Stock Markets
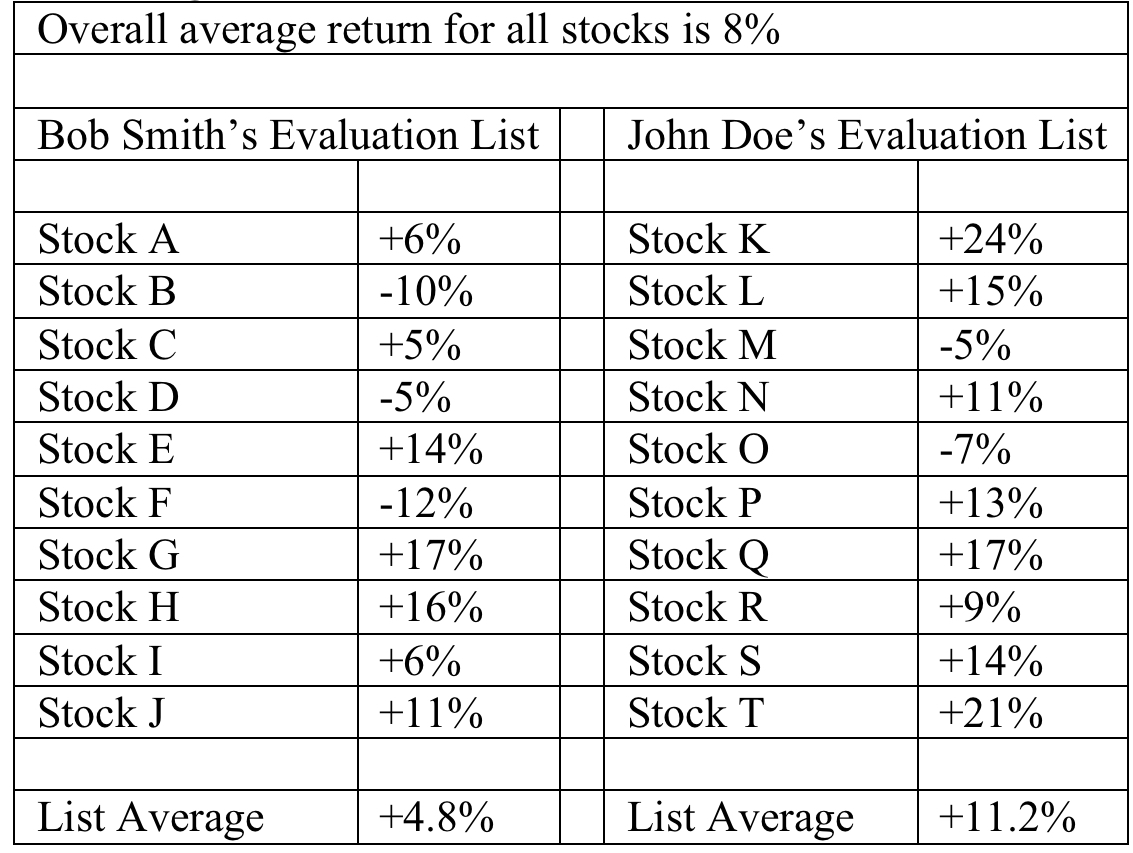
Suppose John picked one stock from his list randomly. There’s no guarantee he’d have done well. But eight out of 10 stocks on his list performed better than the 8% overall average. So there’s an 80% probability he could have beaten the market simply by drawing a ticker out of a hat. Meanwhile, Bob’s list contained four stocks that beat the overall market average. So had he selected randomly, there was a four out of ten (40%) probability that he’d have outperformed the market. Bob certainly could have helped himself through superior individual stock evaluation. Perhaps his skills might have helped him identify the top three stocks on his list. In that case, his average return would have jumped to an impressive 15.7%. But if he really was such a good analyst, it would have been a shame for him to waste his time looking at so many dogs. Suppose he devoted his talents to evaluating the stocks on John’s list. If Bob can identify the top three stocks there, his average return would jump to 20.7%. On the other hand, suppose Bob’s evaluation skills are poor and he consistently gravitates toward the worst three stocks. Using his list, the average return will be –9%. But if he were to work with John’s list, the impact of his analytic errors would be mitigated. The worst three stocks there had an average return of –1%.
Every investor can benefit from using superior lists. Even though there are good stocks on Bob’s List and bad stocks on John’s list, it’s probable that over time, anyone would do better with a list such as the one created by John, whether one’s stock evaluation skills are good, average or weak.
Screening — The Penultimate Idea Generator
Screening, as used in this context, refers to the practice of creating and/or using a set of specifically-stated yes-no questions that address an aspect of what you regard as an attractive stock opportunity. If a stock generates a “yes” answer to each question, it’s worth analyzing. If there is a single negative answer, pass on it.
Screening can be done in many ways, the purest of which is a set of yes-no questions that are phrased in terms specific enough to be answered through a computerized data query.
- Here’s an example of a valid screening query rule: Is the P/E ratio with earnings based on the consensus estimate of next-years EPS below 20?
- In contrast, there’s this: Is the stock reasonably valued?
The latter could only be valid if it’s tied to a specific objective data-referencing criterion, or set of criteria, that defines reasonable valuation. If you set up a value-oriented ranking system, you could, then use if to screen for value by asking, for example:
- Is the score under XYZ Value Ranking System greater than 80? (This is actually a pretty good approach since it allows you to find stocks that excel in different ways, so long as they excel in something, or stocks that may not excel in any one way but are pretty darned good in a lot of ways.)
Here’s another approach:
- When XYZ Value Ranking System is applied to the S&P 500 constituents, does the rank of this stock fall within the top 20?
Many of today’s more traditional, statistically-inclined “quants” work in this manner, and often won’t use the word screening to describe what they’re doing. Major style-based ETFs, for example, will have a variety of very broad traditional-sounding screening rules addressed to size, liquidity, country of origin, etc and then conclude with use of a ranking system that gives “yes” answers to stocks that pass the preliminary rules and are also in the top 20%, 50%, etc. of the remaining universe.
Speaking for myself, I prefer to give a larger role to more traditional screening rules. For example, if I’m using a Value Ranking system to pick a number of top-ranked stocks, I want to enhance the probability of getting good results by trying, as best I can, to preliminarily screen out situations for which low P/E etc. is likely to give bad results, such as poor growth and/or poor company quality (value traps). It’s a matter of choice.
The benefits of working this way are described later in Chapter 4 of Screening the Market:
Using stock screens to generate Evaluation Lists frees you from a variety of restraints on your selection efforts. It doesn’t matter what magazines, newspapers or Web commentators you read. It doesn’t matter which financial TV or radio broadcasts you see or hear. It doesn’t matter where you live, what you do, or what companies you come into contact with in your day-to-day life. If you screen, there’s only one thing that counts. A stock will get onto your Evaluation List if it passes a series of objective tests that were established based on your investment preferences.
This sounds extremely sensible. But be warned that the habits eliminated by screening, however detrimental they may be, do have one thing going for them. They are comfortable. Once you start screening, you’ll need to brace yourself for two changes: (1) Many names that are well known to you for a variety of reasons will be omitted from your screens. (2) Your screens will include many companies that are completely unfamiliar to you.
The upside is the number of true gems you can find. This can do wonders for your stock portfolio. When I look at my best successes over the years, I notice two themes: (1) Many were names I never heard of until they started appearing in my screens. (2). Many flourished at a times when high-profile stocks floundered.
(The italicized portion is a paraphrased version of the original text.)

© Can Stock Photo / PixeslAway
Evaluating Screen “Performance”
It’s natural to wonder if, and to what extent, screens really have the potential to perform the role suggested above in the Table. Can they really narrow a large investment universe in such a way as to help an investor make choices from a “better” subset?
Nothing is for certain. Investing in equities requires that we deal with the unknowable future and, as we know, past performance does not assure future outcomes. (That’;s not just regulatory boilerplate. It’s also the truth.) But can make reasonable use of historical data and backtests (the latter are statistical studies that show the results that could have been achieved in the past had the screen been created earlier). The key word is “reasonable.”
It is not reasonable to count on your results matching those depicted in a backtest because things change. You especially cannot rely on test results if the rationale for the way the screen was set up sounds anything like “many things were tried and this is what worked.” Financially logical reasons for the choices of criteria is absolutely mandatory. The logic is what allows us to bridge the gap between past and future, and even at that disappointment can occur. For example, we know value has a great long-term track record, but the market has lately been apathetic at best toward value and more enthusiastic about potential future growth. (So if you believe in the logic of your approach, you can go forward even in the face of bad backtest results if you can plausibly assume market attitudes will change, as I did in this post.
Case Study: A Real-Life Screen
For a review of my real-money experiences with screens I used to own everything (rigidly buy and sell as stocks went into and out of the model), click here.
At this time, let’s take a close look at test data for a screen that’s included in the group of “starter screens” recently introduced on Chaikin Analytics. (I’ll discuss the screen logic and some passing stocks in subsequent posts, but for now, I’ll say it’s the Bullish Swing Trade screen.)
I’ll illustrate here the results of a ten-year test that assumes quarterly reconstitution. In other words, the screen is run at the beginning of quarter 1 and it is assumed an equal dollar amount is invested into each stock. Then, at the start of quarter 2, we start all over again. We forget about the stocks we previously had. We rerun the screen and assume a new portfolio that is equally invested in all passing stocks. And so on until the end of the 40th quarter, the 10th year.
For each of the 40 samples, the average total returns (share price gain or loss plus dividends if any) are computed for each of two groups. Group 1 (in the chart, it’s labeled using the statistical jargon, Quantile 1) consists of those stocks that pass the screen. Quantile 2 consists of all the others.
This is not meant to serve as a simulation of a life-like portfolio. Nor is is it meant to mathematically or statistically model the whole market in a quest for universal investment truths, which is what traditional quant models aim to do. I’m seeking instead to test the efficacy of something designed to help investors focus their time, energy and skills on a small, manageable-sized group of stocks that has the potential to be, on the whole, better than the full universe.
In this particular screen, Quantile 1, the number of potentially actionable ideas) averaged 104. That’s still a lot. But we can narrow further by continuing to screen. For example, I also divided the group into large- mid- and small-cap within the Russell 3000, each of which had a little more than 30 stocks.
What’s significant for this initial test is that we’re comparing about 100 screened stocks to about 2,900 others. If we have reason to believe the group of 100 is better than the group of 2,900, then we will have delivered on what Table 4.1 above suggested we should aim for, a potentially superior user-defined personal stock market from which we can get pre-qualified ideas. So much the better if we can add additional criteria and get down to 30 or fewer stocks, as I typically do when I screen for real-money use.
So now, let’s look at the results;
Figure 1 paints the sort of picture most familiar to those who want to see simulated portfolios. That’s not really what this is. The graph plots are not total returns but “active returns” which are total returns minus benchmark returns for Quantile 1, the 100 or so passing stocks versus the active returns for Quantile 2, the 2,900 or so failing stocks).
Figure 1
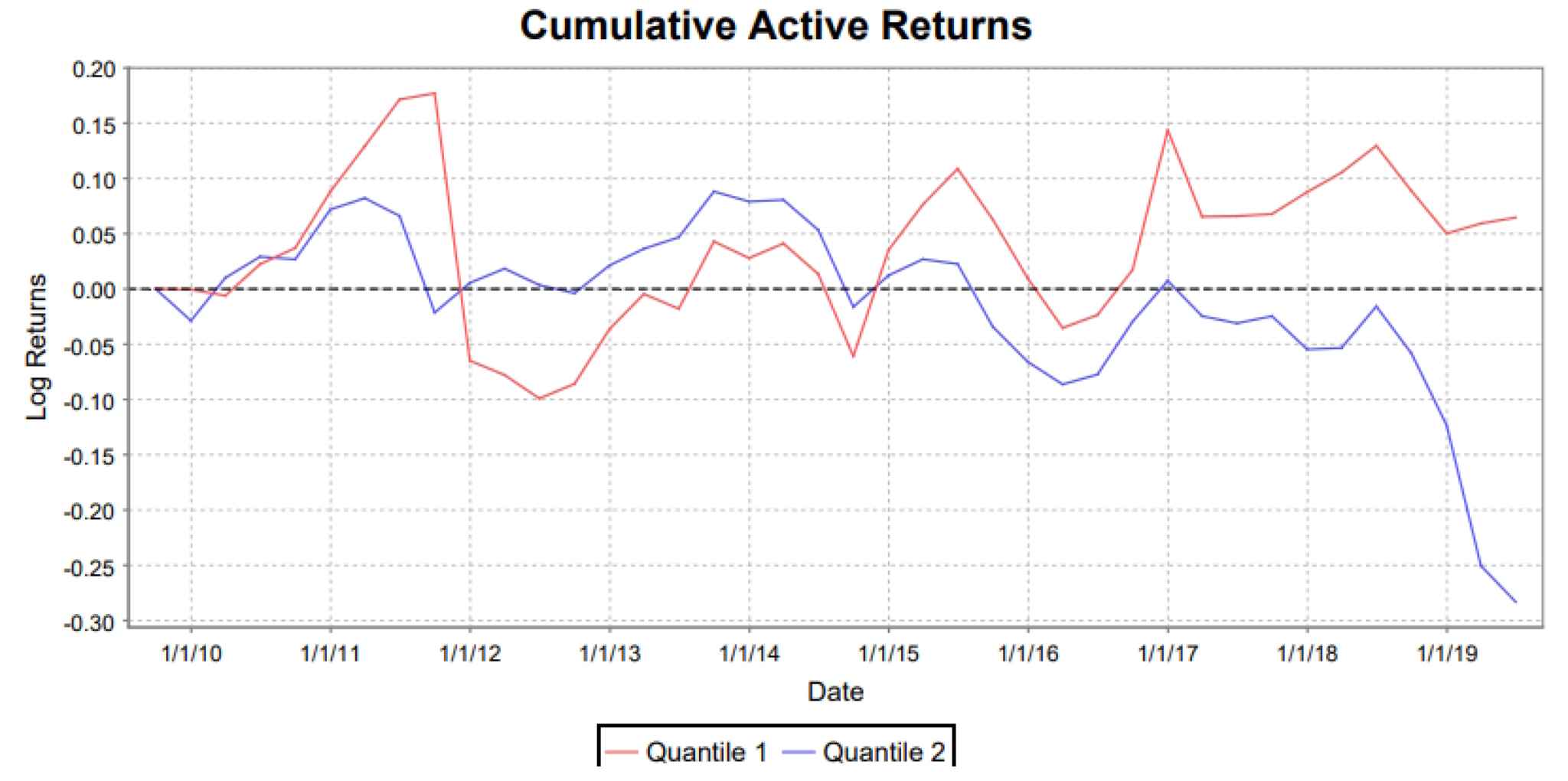
Red is Quantile 1 (passing stocks); Blue is Quantile 2 (did not make it into the screen). Image from ClariFi, a subsidiary of S&P Global Market Intelligence
It’s interesting, but not necessarily my favorite presentation. For one thing, it’s easy for me to let my guard down and wind up reacting as if I were seeing a genuine portfolio-to-benchmark simulation. Second,I have to stay on my toes to remain aware of how heavily the picture is influenced by the choice of starting date and/or an atypically sharp move in one particular period.
Figure 2 is the view that most satisfies those looking for answers that are as black-and-white as possible. It shows the average annualized active return for each quantile. Its strength is simplicity. But that simplicity is also its weakness; it can mask a lot of things going on from period to period.
Figure 2
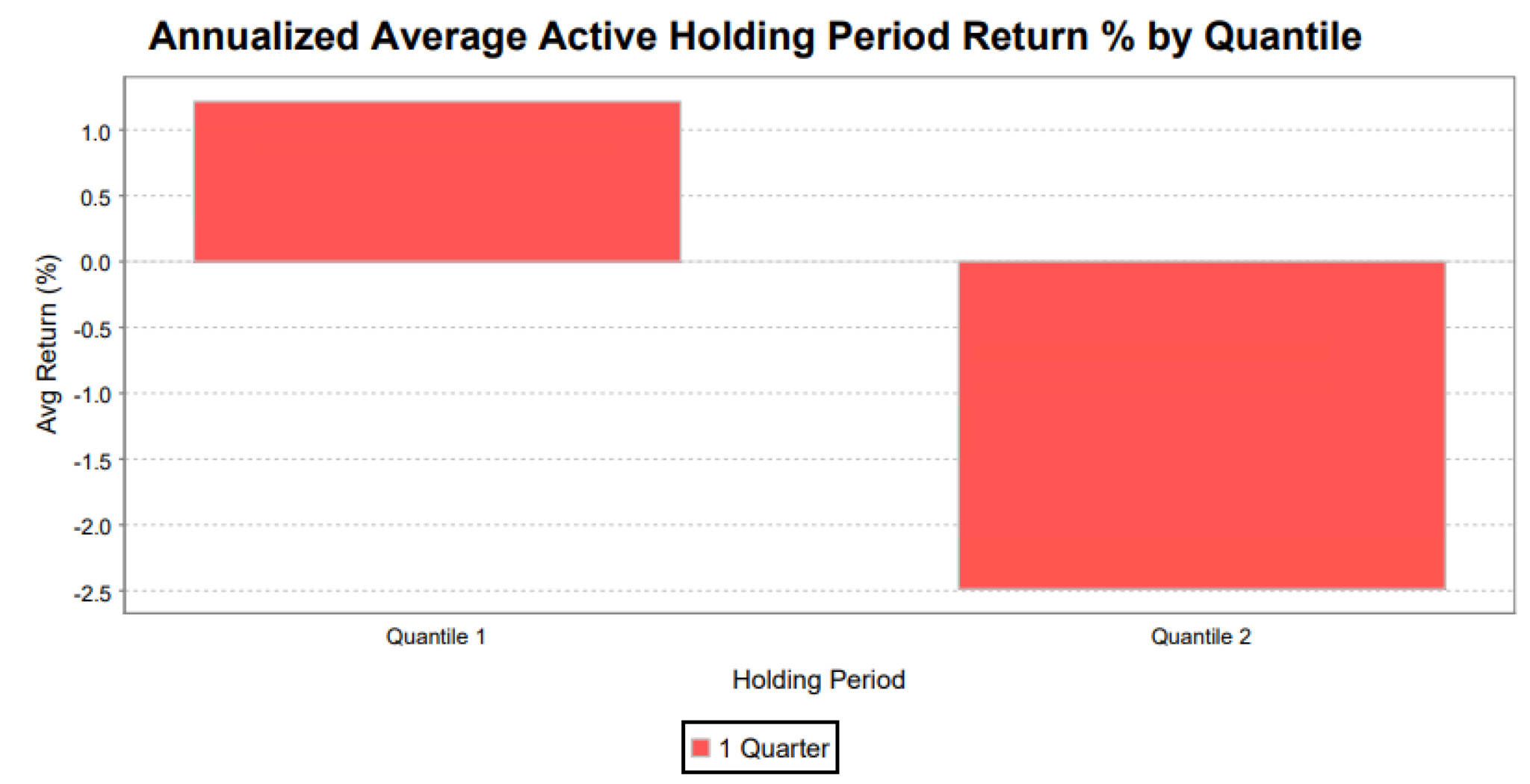
Image from ClariFi, a subsidiary of S&P Global Market Intelligence
My favorite view is the one shown in Figure 3.
For each period (quarter in this case, but it could be anything; a week, a month, etc.) we see a graph of the return of Quantile 1 (the 100 or so stocks in the screen) minus Quantile 2; the “spread” between the two groups.
It doesn’t give a simple yes-no answer, but it is the presentation that I think gives the greatest picture of screen performance (or at least as good a picture as one can get without diving into the numerical tables).
Since we’re dealing with Quantile 1 minus Quantile 2, we obviously prefer to see as many bars as possible stretching upward above the zero line. Upward bars that stretch higher up are better. And to the extent we have downward reaching basrs, we’d ideally like them to be as shallow as possible.
Figure 3
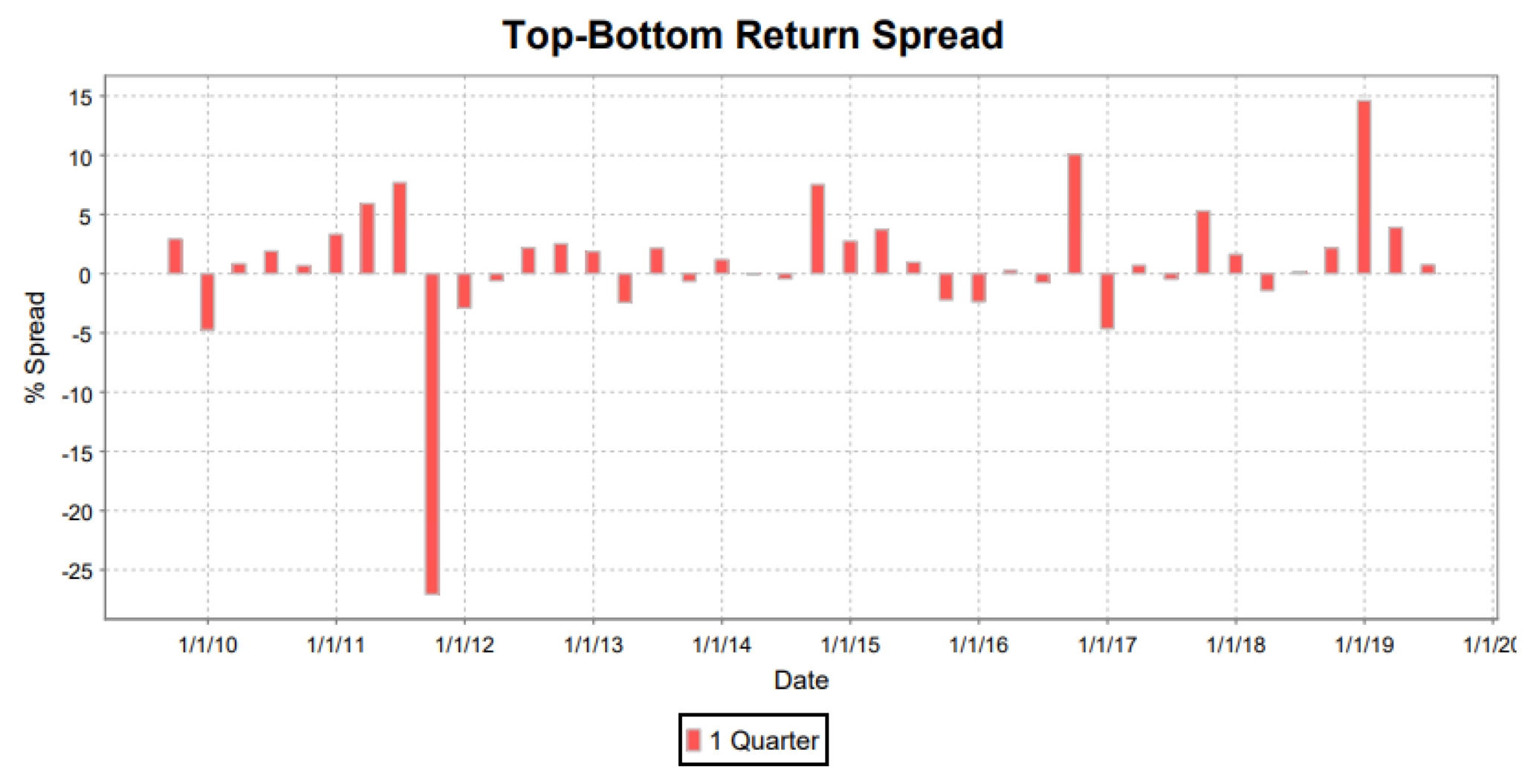
Image from ClariFi, a subsidiary of S&P Global Market Intelligence
The illustration here depicts a very successful backtest. We see only one really deep downward bar and it happened a long time ago, and looking at the date, I recall a lot of aberrant negative things happening in the market back then (the Arab Spring, the Greek-Euro crisis, etc.). That one nightmare quarter is what prevented the pseudo-simulation depicted in Figure 1 from having a more impressive appearance.
Conclusion
Again, and I can’t say this often enough: When we’re dealing with the unknowable future, nothing is guaranteed. (Just imagine yourself a back in time to a few weeks before the 2011 horror quarter.) We’re working with probabilities, as we necessarily must since nobody can know the future. But as far as enhancing probabilities, if a screen can do for me the sort of thing depicted in the hypothetical table presented above, if it can help me create a personal stock market from which to draw ideas, I’ll take it. Figure 3 is an illustration of a screen that does just this.
